Flume NG 基本架构及原理
前言
由于数据量不是特别大,因此我们在使用Flume的时候没有使用分区,基本上就是在业务端的web server上部署了一个agent,然后输出到hdfs上。
部署
kafka 数据源
可以参考我的另一篇文章,里面讲了我在工作中遇到的定制的kafka source。
tail 数据源
flume ng里面可以使用Exec Source来代替。其实就相当于执行了一个tail -f 的的命令。
Note You can use ExecSource to emulate TailSource from Flume 0.9x (flume og). Just use unix command
tail -F /full/path/to/your/file. Parameter -F is better in this case than -f as it will also follow file rotation.
示例。
a1.sources = r1a1.channels = c1a1.sources.r1.type = execa1.sources.r1.command = tail -F /var/log/securea1.sources.r1.channels = c1spooldir 数据源
在 /etc/flume/conf 目录创建 f2.conf 文件,内容如下:
agent-1.channels = ch-1agent-1.sources = src-1agent-1.channels.ch-1.type = memoryagent-1.sources.src-1.type = spooldiragent-1.sources.src-1.channels = ch-1agent-1.sources.src-1.spoolDir = /root/logagent-1.sources.src-1.fileHeader = trueagent-1.sinks.log-sink1.channel = ch-1agent-1.sinks.log-sink1.type = loggeragent-1.sinks = log-sink1关于 Spooling Directory Source 配置说明,请参考 Spooling Directory Source接下来启动 agent:
$ flume-ng agent -c /etc/flume-ng/conf -f /etc/flume-ng/conf/f2.conf -Dflume.root.logger=DEBUG,console -n agent-1然后,手动拷贝一个文件到 /root/log 目录,观察日志输出以及/root/log 目录下的变化。
示例配置
主要是官网介绍的几种情况。
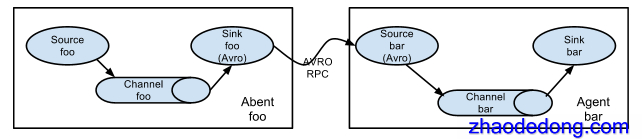
多个 agent 顺序连接
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
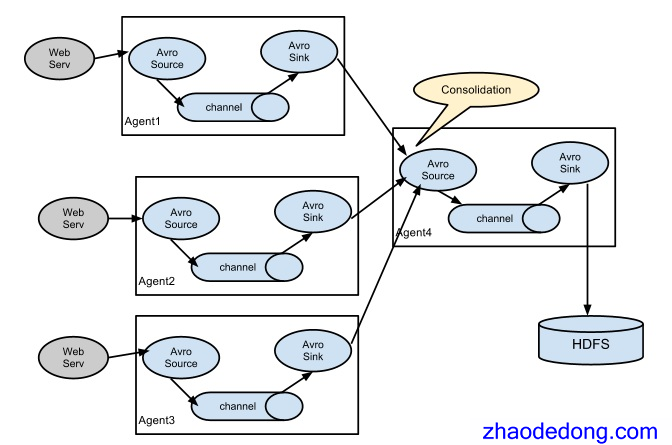
多个Agent的数据汇聚到同一个Agent
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志,Web网站为了可用性使用的负载均衡的集群模式,每个节点都产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
多路(Multiplexing)Agent
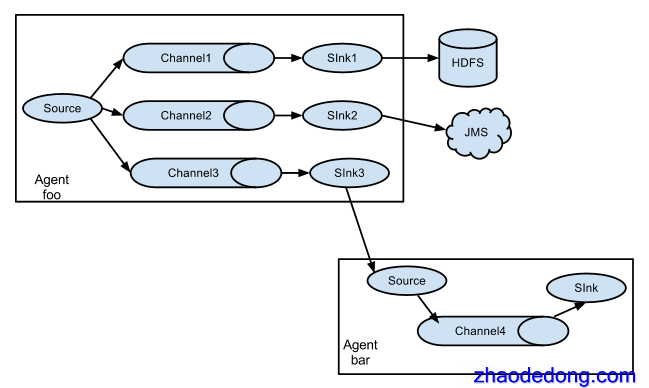
这种模式,有两种方式,一种是用来复制(Replication),另一种是用来分流(Multiplexing)。Replication方式,可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的。
配置格式示例如下:
# List the sources, sinks and channels for the agent<Agent>.sources = <Source1><Agent>.sinks = <Sink1> <Sink2><Agent>.channels = <Channel1> <Channel2># set list of channels for source (separated by space)<Agent>.sources.<Source1>.channels = <Channel1> <Channel2># set channel for sinks<Agent>.sinks.<Sink1>.channel = <Channel1><Agent>.sinks.<Sink2>.channel = <Channel2><Agent>.sources.<Source1>.selector.type = replicating上面指定了selector的type的值为replication,其他的配置没有指定,使用的Replication方式,Source1会将数据分别存储到Channel1和Channel2,这两个channel里面存储的数据是相同的,然后数据被传递到Sink1和Sink2。
Multiplexing方式,selector可以根据header的值来确定数据传递到哪一个channel,配置格式,如下所示:
# Mapping for multiplexing selector<Agent>.sources.<Source1>.selector.type = multiplexing<Agent>.sources.<Source1>.selector.header = <someHeader><Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1><Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2><Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2>#...<Agent>.sources.<Source1>.selector.default = <Channel2>上面selector的type的值为multiplexing,同时配置selector的header信息,还配置了多个selector的mapping的值,即header的值:如果header的值为Value1、Value2,数据从Source1路由到Channel1;如果header的值为Value2、Value3,数据从Source1路由到Channel2。
实现load balance功能
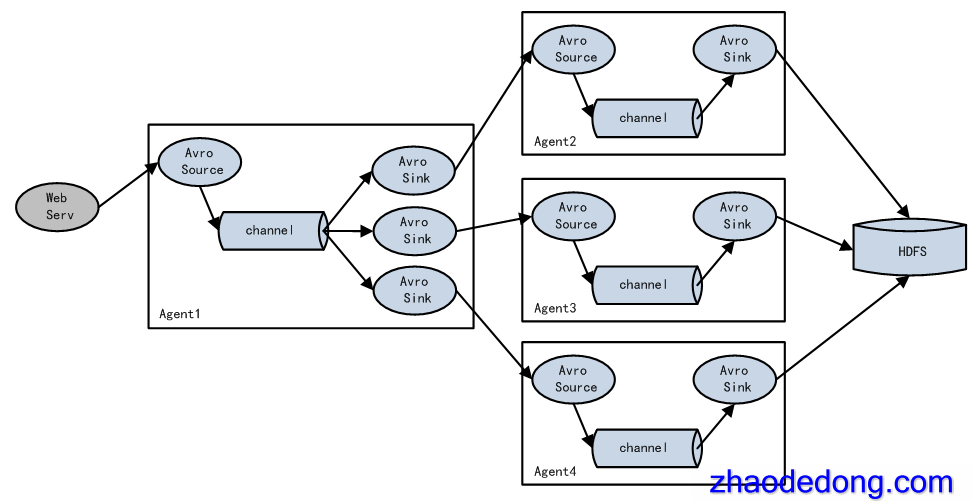
Load balancing Sink Processor能够实现load balance功能,上图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上,示例配置,如下所示:
a1.sinkgroups = g1a1.sinkgroups.g1.sinks = k1 k2 k3a1.sinkgroups.g1.processor.type = load_balancea1.sinkgroups.g1.processor.backoff = truea1.sinkgroups.g1.processor.selector = round_robina1.sinkgroups.g1.processor.selector.maxTimeOut=10000实现failover能
Failover Sink Processor能够实现failover功能,具体流程类似load balance,但是内部处理机制与load balance完全不同:Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。如果一个Sink能够成功处理Event,则会加入到一个Pool中,否则会被移出Pool并计算失败次数,设置一个惩罚因子,示例配置如下所示:
a1.sinkgroups = g1a1.sinkgroups.g1.sinks = k1 k2 k3a1.sinkgroups.g1.processor.type = failovera1.sinkgroups.g1.processor.priority.k1 = 5a1.sinkgroups.g1.processor.priority.k2 = 7a1.sinkgroups.g1.processor.priority.k3 = 6a1.sinkgroups.g1.processor.maxpenalty = 20000